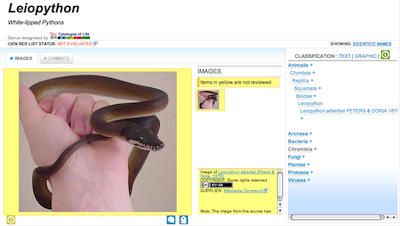
Last month EOL took the brave step of including Wikipedia content in its pages. I say "brave" because early on EOL was pretty reluctant to embrace Wikipedia on this scale (see the
report of the Informatics Advisory Group that I chaired back in 2008), and also because not all of EOL's curators have been thrilled with this development. Partly to assuage their fears, EOL displays Wikipedia-derived content on a yellow background to flag its "unreviewed" status, such as this image of the python genus
Leiopython:
It's interesting to compare EOL's approach to Wikipedia with that taken by the BBC, as documented in
Case Study: Use of Semantic Web Technologies on the BBC Web Sites. The BBC makes extensive use of content from community-driven external sites such as
MusicBrainz and Wikipedia. They embed the content in their own pages, stating where the content came from, but not flagging it as any less meaningful or reliable than the BBC's own content (i.e., no garish yellow background).
Furthermore, the BBC does two clever things. Firstly:
To facilitate integration with the resources external to bbc.co.uk the music site reuses MusicBrainz URL slugs and Wildlife Finder Wikipedia URL slugs. This means that it is relatively straight forward to find equivalent concepts on Wikipedia/DBpedia and Wildlife Finder and, MusicBrainz and /music.
This means that if the identifier for the artist Bat for Lashes in Musicbrainz is
http://musicbrainz.org/artist/10000730-525f-4ed5-aaa8-92888f060f5f.html, the BBC reuse the "slug"
10000730-525f-4ed5-aaa8-92888f060f5f and create a page at
http://www.bbc.co.uk/music/artists/10000730-525f-4ed5-aaa8-92888f060f5f. Likewise, if the Wikipedia page for
Varanus komodoensis is
http://en.wikipedia.org/wiki/Komodo_dragon, then the BBC Wildlife Finder page becomes
http://www.bbc.co.uk/nature/species/Komodo_dragon, reusing the slug
Komodo_dragon.
Reusing identifiers like this can greatly facilitate linking between databases. I don't need to do a search, or approximate string matching, I just reuse the slug. Note that this is a two-way thing, it is trivial for Musicbrainz to create links to BBC information, and visa versa. Reusing identifiers isn't new, other examples include Amazon.com's ASIN (which for books are ISBNs), and BHL reuses uBio NameBankIDs -- want literature that mentions the Komodo dragon? Use the uBio
NameBankID 2546401 in a BHL URL
http://www.biodiversitylibrary.org/name/2546401.
The second clever thing the BBC does is treat the web as a content management system:
BBC Music is underpinned by the Musicbrainz music database and Wikipedia, thereby linking out into the Web as well as improving links within the BBC site. BBC Music takes the approach that the Web itself is its content management system. Our editors directly contribute to Musicbrainz and Wikipedia, and BBC Music will show an aggregated view of this information, put in a BBC context.
Instead of separating BBC and Wikipedia content (and putting the later in quarantine as does EOL), the BBC embraces Wikipedia, editing Wikipedia content if they feel a page need improving. One advantage of this approach is that it avoids the need for the BBC to replicate Wikipedia, either in terms of content (the BBC doesn't need to write its own descriptions of what an organism does) or services (the BBC doesn't need to develop tools for people to edit the BBC pages, people use Wikipedia's infrastructure for this). Wikipedia provides core text and identifiers, BBC provides its own unique content and branding.
EOL is trying something different, and perhaps more challenging (at least to do it properly). Given that both EOL and Wikipedia offer text about organisms, there is likely to be overlap (and possibly conflict) between what EOL and Wikipedia say about the same taxon. Furthermore, there will be duplication of information such as bibliographic references. For example, the Wikipedia content included in the EOL page for
Leiopython contains a bibliography, which includes these references:
Hubrecht AAW. 1879. Notes III on a new genus and species of Pythonidae from Salawatti.
Notes from the Leyden Museum 14-15.
Boulenger GA. 1898. An account of the reptiles and batrachians collected by Dr. L. Loria in British New Guinea.
Annali del Museo Civico de Storia Naturale di Genova (2) 18:694-710
The genus name
Leiopython was published by Hubrecht (1879), and Boulenger (1898) is cited in support of a claim that a distribution record is erroneous. Hence, these look like useful papers to read. Neither reference on the Wikipedia page is linked to an online version of the article, but both have been scanned by EOL's partner BHL (you can see the articles in BioStor
here, and
here, respectively)
1.
Problem is, you'd be hard pressed to discover this from the EOL page. The BHL results do list the journal
Notes from the Leyden Museum, but you'd have to visit the links manually to discover whether they include Hubrecht (1879) (they do, as well as various occurences of
Leiopython in the indices for the journal). In part this problem is a consequence of
the crude way EOL handles bibliographies retrieved from BHL, but it's symptomatic of a broader problem. By simply mashing EOL and Wikipedia content together, EOL is missing an opportunity to make both itself and Wikipedia more useful. Surely it would be helpful to discover what publications cited on Wikipedia pages are in BHL (or in the list of references for hand-curated EOL pages)? This requires genuine integration (for example by reusing existing bibliographic identifiers such as DOIs, and tools such as OpenURL resolvers). If it fails to do this, EOL will resemble crude pre-Web 2.0 mashups where people created web pages that had content from external sites enclosed in <IFRAME> tags.
The contrast between the approaches adopted by EOL and the BBC is pretty stark. The BBC has devolved text content to external, community-driven sites that it thinks will do a better job than the BBC could alone. EOL is trying to integrate Wikipedia into it's own text content, but without addressing the potentially massive duplication (and, indeed, possible contradictions) that are likely to arise. Perhaps it's time for EOL to be as brave as the BBC, as ask itself
whether it is sensible for EOL to try and occupy the same space as Wikipedia.
1. Note that the bibliographic details of both papers are wanting, Hubrecht 1879 is in volume 1 of Notes from the Leyden Museum, and Annali del Museo Civico de Storia Naturale di Genova series 2, volume 18 is also treated as volume 38.